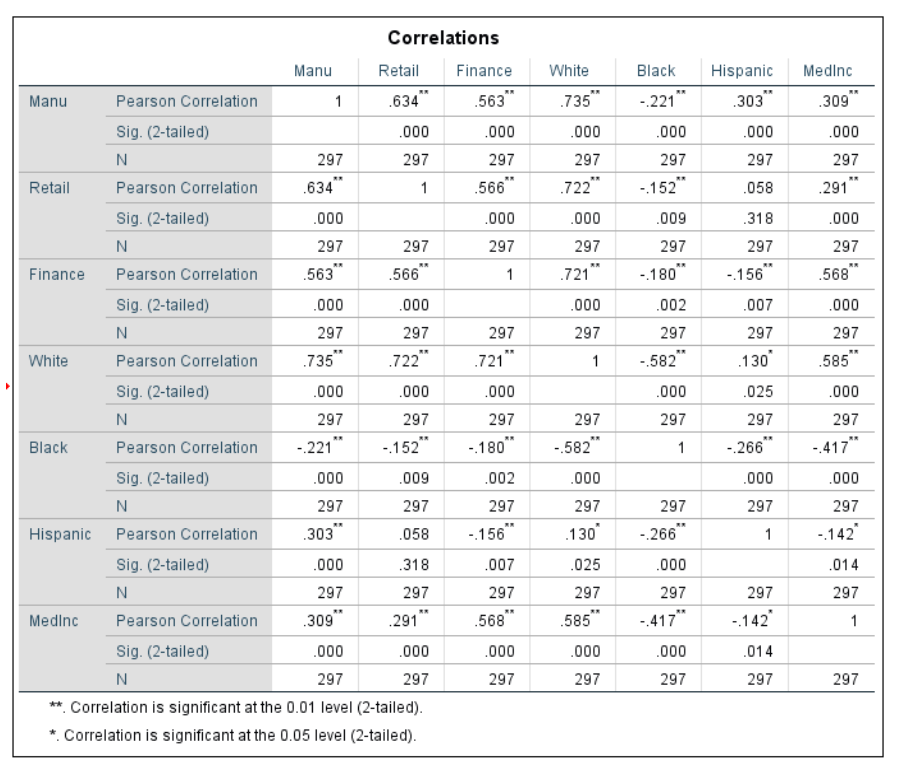
Data was given with percent of kids receiving free lunch and the crime rates in different neighborhoods of Town X. There is a theory that as the percent of kids receiving free lunch increases, so does the crime rate. To test this theory, a regression test was ran in SPSS. Regression tests are used to predict the effect of one variable on another, it investigates causation. After running the test, the results showed that the slope, B, was larger than 0 (1.685), indicating a positive relationship. However, because the b value is still small, the best fit line will still be flatter. T test the strength of the regression, we use the coefficient of determination, or r^2. The value given by SPSS was .173. This uses the independent variable to account for the variation in the dependent variable, which ranges on a scale of 0 to 1. We want the points in the best fit line to be as close as possible to have a stronger relationship. Because the r squared value was closer to 0, this means that there is quite a bit of variation in the amount of variation in Y (Crime Rate) that can be explained by X (percent free lunch). If a new area in town was identified as having 23.5% with free lunch, we can use the regression analysis equation y=a+bx to find the corresponding crime rate. SPSS gives us the constant value, the point where the best fit line crosses the X axis a, 21.82, and the b value, the slope of the line which shows the responsiveness of the dependent variable to the independent variable, 1.685. So if we plug in 23.5% as the X in the equation we get 61.418. However, because the coefficient of determination, r squared value, is so low, we can not be very confident in this result. There is variation about how much X explains Y. On a scatter plot, the points would not be close to the best fit line, or the sum of the distances from the points to the fitted line. In this case, there would be a high amount of residuals, or deviation of the points from the line, so there is a difference between the actual and predicted value of crime rate. The results from SPSS are shown below.


Part 2:
Introduction:
Using the data provided for 911 calls in Portland Oregon, a company is interested in building a new hospital and are wondering about the location and size the hospital should be. They want to know the factors that would explain where the majority of the calls come from. Using a variety of variables in an Excel file and shapefile, I will run single regression tests in SPSS, create a choropleth map and residual map, and run multiple regression tests to determine the influences related to the calls and where the best place might be to build the hospital based off the calls.
Methods:
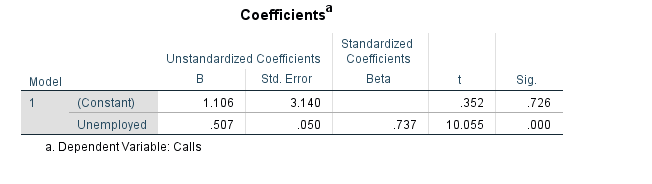
Step 1: The first step involves running a single regression analysis in SPSS using the Excel sheet of 911 calls in Portland. Using Calls as the dependent variable, I then picked three separate independent variables to test against it. The independent variables I chose to run were Alcohol Sales (AlcoholX), Unemployed, and Number of College Grads (CollGrads). Looking at the R Squared values, slope, constant, and significance values for each output (found in the results section), I made conclusions.
Step 2: To obtain a visual of the number of 911 calls in each Census Tract, a choropleth map was made. I chose a graduated colors map for this, with jenks natural breaks classification and 5 classes. The map is shown in figure 1 in the results. The next map that needed to be made was a Standardized Residual map showing the independent variable I tested with the largest R squared value, which was Unemployed numbers. In arcGIS, using the OLS option under spatial statistics tools, I generated a map showing standard deviations of residuals for Unemployed numbers in relationship with number of 911 calls (figure 2). This shows how each tract deviates from the regression line.
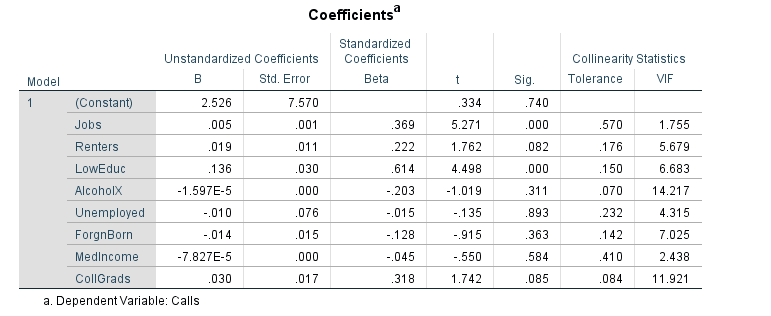
Step 3: Next, in SPSS I ran a multiple regression report for all of the variables listed: (Calls
(number of 911 calls per census tract), Jobs, Renters, LowEduc (Number of
people with no HS Degree), AlcoholX (alcohol sales), Unemployed, ForgnBorn
(Foreign Born Pop), Med Income, CollGrads (Number of College Grad)). I turned on col linearity diagnostics to test for multicollinearity. This would show if any two of the variables above are correlated with each other and possibly changing the significance level. Lastly, a step wise approach was used with all the variables and a map was made from the results (figure 3).
Results:
Step 1 (single regression): The first variable I ran as the independent variable was Alcohol Sales. First, looking at the slope, b, in these results we can see that it is very tiny (3.069E^5), almost the equivalent of 0, so the best fit line is flat. The best fit line would fit a line through the set of data points so the sum of the squared vertical distances of the observed points to the line is minimized. So by looking at the slope equation we can see that for every one alcohol sale there is an increase in 911 calls by 3.069E^-5, which is basically nothing. by looking at the R squared value, we can see that the independent variable of alcohol sales is not a very strong predictor of 911 calls. So the strength of this relationship is not very strong because r squared is closer to 0 (.152) meaning alcohol sales do not explain 911 calls very much at all. This also means that not very many points would be picked up, or follow the best fit line. The null hypothesis in this case would state that there is no relationship between the X and the Y variables, and because we have a significance level of .049, this means that we reject the null. There is a relationship but the strength is low.





Step 2 (choropleth and residual map):
The map (figure 1) below shows that the highest number of 911 calls occur in the center of the city, the class containing the most calls (67-176) occurring in the middle of the city and stretching to the north and south borders in the middle. Almost all tracts on the east and west side of the city have classes containing the fewest amount of calls.
The next map (figure 2) shows how much each tract deviates from the regression line of the moderately correlated relationship between Unemployment numbers and the number of 911 calls in the city. The darker red colors which occur in the center of the city indicate that these tracts contain values which deviate above the value calculated by the best fit line, so they would contain higher numbers of calls made than the value of calls indicated at the line for that particular value of Unemployed people. We can see that this relates to the first map, with the higher number of calls occurring in the center of the city. We can also see that the tracts shaded in blue contain values that deviate below the regression line at a value for Unemployed. The darker blue the tract is, the farther it falls below the line for a certain point. The blue falls mostly on the east and west half of the city. About half the tracts on the map contain values which deviate above or below the standard deviation (tracts which are not yellow). This corresponds with the r squared value of .543 because r squared shows how many tracts indicate variation in the explanation of the Y variable. So about half the tracts have Y values which are different from the predicted value of Y at that point, or half explain the variation between 911 Calls and Unemployment.
 |
| Figure 1 |
 |
| Figure 2 |



 |
| Figure 3 |